Measurement
简介
这里是一个对于经典网络测量工作的总结,目前包括:
主动测量:
被动测量:
- FlowRadar(NSDI’16)
- LossRadar(CoNext’16)
- UnivMon(SIGCOMM’16)
- Passive Realtime Datacenter Fault Detection and Localization(Facebook, NSDI’17)
- Elastic Sketch(SIGCOMM’18)
- PINT(SIGCOMM’20)
- DART(SIGCOMM’22)
- ChameleMon(SIGCOMM’23)
网络测量的目的是以一定粒度对整个网络的性能表现进行分析,其中性能表现包括但不限于:时延、丢包率、抖动等。
从测量方式上分类,分为主动测量和被动测量两种:主动测量一般会由服务端主动发起 Ping 请求(或修改过的基于 TCP 的 Ping 等)主动探测网络性能,被动测量通过部署流量监控套件收集信息进行在线或离线的分析。由于广域网结构复杂,且 ISP 内事件和架构对厂商不可见,因此主动拨测常用于内网的故障检测;在 ISP 对接的 POP 点部署被动测量监控广域网往往是一个更好的方案。并且,被动测量不用向网络中注入额外流量,更容易做到细粒度的测量,便于故障定界。
Pingmesh
Pingmesh 由微软提出,已经在微软 DCN 内大规模部署(AliPing 也使用了该方案)。Pingmesh 使主机主动发起并回复 Ping 请求,通过监测 Ping 请求的完成时间对 DCN 间链路进行测量。同时,Pingmesh 能够作为一个背景服务保持长期上线,因此能够无间断地,甚至在服务上线之前收集并分析网络数据。
Pingmesh 将 DCN 的拓扑抽象为三个层级:主机、机架、机房;Pingmesh 希望能够做到链路的 100% 检测覆盖率(主机间完全图覆盖),即:任意两个主机之间的链路都至少被检测一次。但考虑到 DCN 拓扑,同一个机架内的两台机器对外发送请求时,会使用同一个 ToR 交换机;同一个机房内的两台机器对外发送请求时,也会使用同一个机房交换机;这些节点资源是向下复用的,因此没有必要实现任意两主机之间的完全图覆盖,而仅需要保证:机架内主机的完全图覆盖、机房内机架的完全图覆盖、机房间机房的完全图覆盖即可。机器具体的 Ping 列表生成根据各个机房结构不同,算法差异较大。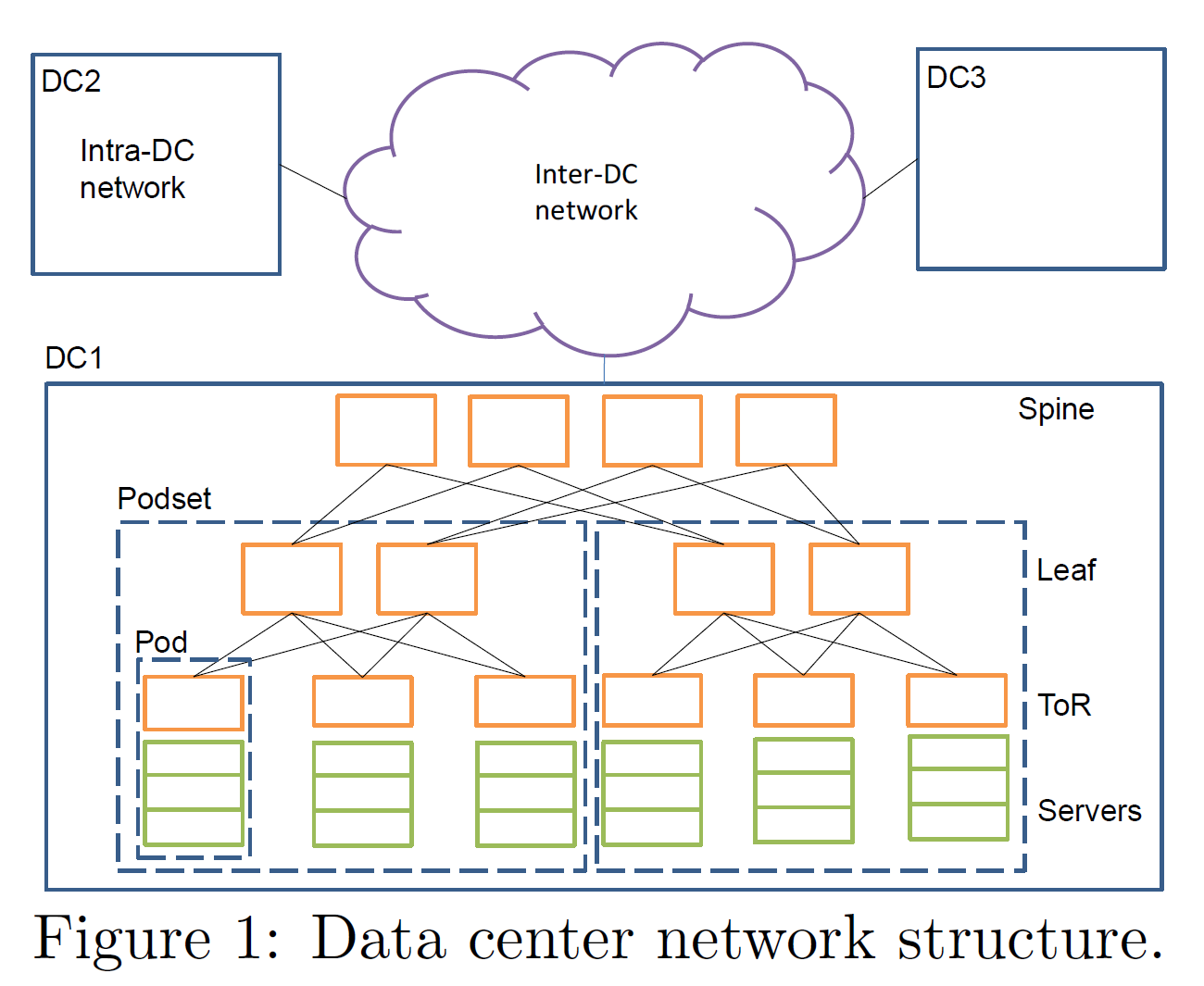
由于 Pingmesh 是端侧的主动拨测方案,每一台 DCN 内的主机都需要部署 Pingmesh 服务。因此 Pingmesh 在实现时需要非常注意跨平台的兼容性和高效率。此外,出于与被检测协议栈解耦的需要,Pingmesh 额外编写了一套轻量级的网络栈,以免在被检测协议栈大规模故障时受到波及。在部署上,Pingmesh 将节点分为:Controller(中心化服务器,负责下发 Ping 表项)、Agent(每一台机器,接收表项并定时 Ping,将数据上传到 DSA)、DSA(中心化服务器,收集 Ping 数据并分析)。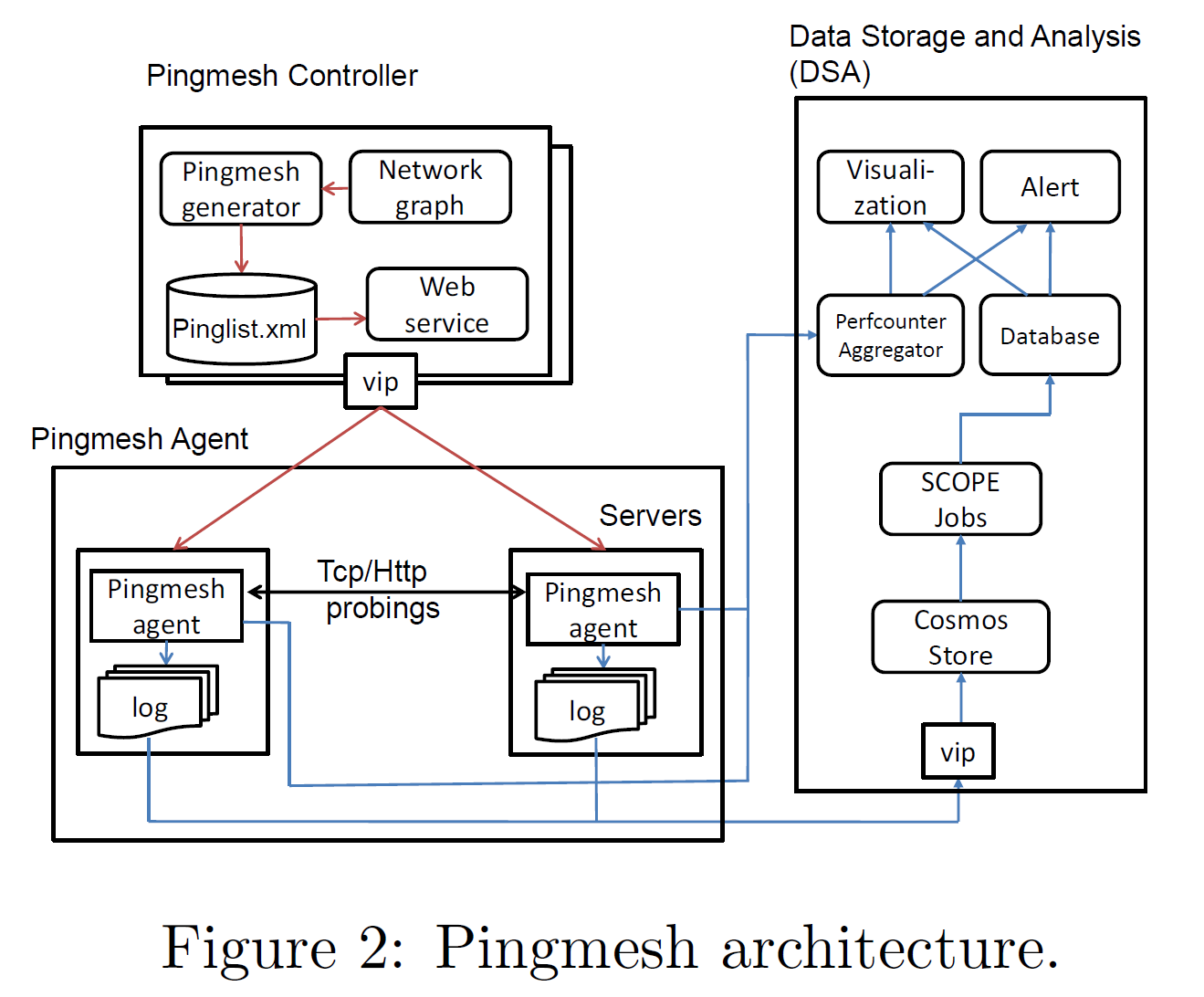
在收集并分析数据时,Pingmesh 主要收集 Ping 的 RTT,该值包括了网络相关的时延(排队时延、传输时延、处理时延)和网络无关的时延(协议栈时延、DMA 数据传输时延等)。Pingmesh 利用了 TCP 流量重传时的指数回退机制,从 SYN 包的传输间隔反推是否产生丢包,从而计算丢包率:
$$DropRate=\frac{ProbesWith3sRTT+ProbsWith9sRTT}{TotalSuccessfulProbes}$$
R-Pingmesh
R-Pingmesh 是将 Pingmesh 扩展到 RoCE 网络中的尝试。出于以下原因,传统的 Pingmesh 并不能直接适用于 RoCE 网络:
- TCP-Pingmesh 不能检测 RoCE 特有的问题(如 PFC)
- TCP 与 RoCE 流量在 RNIC 中会被分为两条独立路径处理
- Pingmesh 只能以端到端的粒度进行检测,无法区分链路上的具体故障(交换机故障/RNIC故障)
- Pingmesh 将所有时延汇总测量,无法区分网络时延和系统时延
- Pingmesh 只能提供最低限度的连通性测试,无法为故障定级
R-Pingmesh 的架构设计与 Pingmesh 大体相似;但由于 RoCE 不存在跨机房流量,因此只需要检测机架内和机架间的流量即可(R-Pingmesh 将该模块称为 Cluster Monitoring)。在此之外,R-Pingmesh 通过针对实际 RMDA 连接的五元组构造 Ping 请求的方式,为实际的流提供了 SLA 的实时监测(该模块称为 Service Tracing)。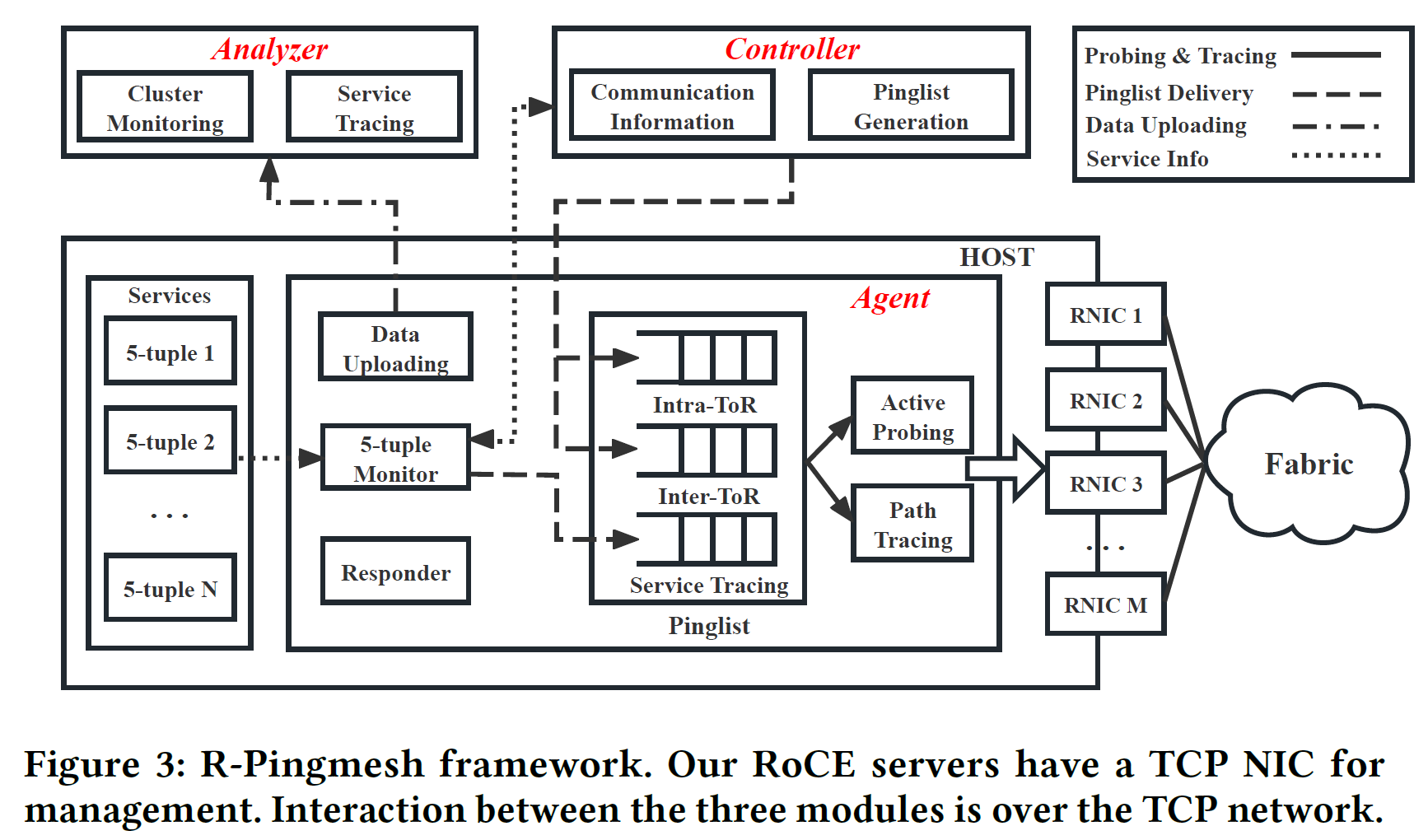
Controller 维护所有 RNIC 的 GID 和 DPN 以分配 Ping 任务,在 RNIC 重启时会主动上报更新。在计算 Pinglist 时,R-Pingmesh 并不保证所有链路都能完全覆盖,而是以 99% 全覆盖的概率随机分配 Ping 任务并下发 Pinglist。Controller 还会负责在 Service Tracing 环节中提供 RNIC 信息。
Actor 使用 RMDA 包封装了一个 Ping。RDMA QP 分为三种:RC、UC、UD;分别可类比为:TCP、带连接的UDP、UDP。由于目标是收集 RTT,因此我们希望在发包和收包时都产生一个时间戳;然而 RC 默认只会在 ACK 之后产生一个有时间戳的 CQE,因此 R-Pingmesh 不考虑使用 RC。又因为 RC 和 UC 都是带连接的,使用时会占用一定 QPC 资源。因此 Actor 考虑利用 UD QP 进行通讯。在具体实现上,使用 eBPF 跟踪 qp 的创建和销毁即可。
Analyzer 的实现较为朴素。在得到异常数据(超时、高 RTT)后,Analyzer 首先排除所有非网络问题(如:机器故障下线、RNIC 重启导致的 QPN Reset 等),这些问题多半是由于 Controller 信息更新不及时导致的,再次使用新版 Controller 信息同步即可排查。对于网络问题,R-Pingmesh 直接按异常路径逐条打标记,标记次数最多的设备判定为异常设备。使用该方案可以实现故障定界和故障定级。
当使用以上的 Cluster Monitoring 得到异常数据后,还可以使用 Service Tracing 进一步追踪,以排除 GPU 死锁、CPU 负载均衡等非网络问题。
RD-Probe
RD-Probe 也是在 Pingmesh 基础上的一个工作。主要适配了华为在现在所使用的一些使得传统 Pingmesh 不能发挥效用的新技术,例如:容器虚拟化、ECMP 随机化、复杂内网路径等。这些技术使得 Pingmesh 不能直接部署在生产环境的容器上,需要进行一次物理结构(De facto topology)到逻辑结构(Vanilla topology)的转化。根据不同的虚拟化技术和随机化技术,在建图上对应到点分裂、边分裂、加边等操作。
另一个比 Pingmesh 有所提升的地方在于:RD-Probe 加入了后段的 Deterministic Probe 环节,用以确保覆盖率能够达标,而不只是依赖于前期的随机化任务生成。Randomized Probe 与 R-Pingmesh 较为类似:根据覆盖率指标参数 $\alpha$ 和 $p$ 计划出总共所需要的 Probing 组数,而后将指标发派到各个主机上随机生成 Pinglist。但这有可能导致覆盖率不足,因此 RD-Probe 为每个物理主机的每个端口额外增加了一个计数器,如果流经这个端口的 Ping 组数不达标,则额外生成 Deterministic Probe 任务直到满足要求。Deterministic Probe 的思想是:选一个较近的邻居 $v$,构造一个 Src 和 Dst 均为 $v$ 的 Ping 包,把本地端口设为 Intermediate。这两套任务生成相结合,在不大量占用额外流量的前提下,确保了端口级的覆盖率达标。


FlowRadar
作者认为:NetFlow 因为要为每个流建表记录,所以需要处理 hash 冲突、及时移除老化流,开销太大。有一些将部分操作转移到控制面或者远程机器上做的方案,但时延、带宽和可用性都有问题;最好还是能在控制面上本地解决。
FlowRadar 直接使用了一个 IBLT 存储流(即:前端一个 Bloom Filter,后端一个 BLT),采用 XOR 模式;解码方式也与 IBLT 相同。
在此基础上,FlowRadar 提出了 Network-wide Decoding 来提高解码成功率。FlowRadar 认为,相邻两个交换机的流有很大程度上的重合;因此在迭代解码过程中,每经过一次迭代,就把当次解码新得到的结果应用在邻居 Switch 上,尝试在邻居 Switch 的 IBLT 中减去该值。
由于可能会出现丢包,这样的做法只能解码出存在哪些流,具体的数据包数量是不准的。因此需要在解码后,根据 IBLT 中记录的数据包数量重建线性方程组进行求解。在求解整数线性方程组时,考虑使用迭代求解,将迭代初始值设定为先前解码得到的不准确解;最终收敛到一个整数精度范围内就算求解成功。
LossRadar
和 FlowRadar 类似,LossRadar 也使用 IBLT。考虑到需要以逐包的粒度测量丢包,LossRadar 在每个交换机的入口和出口处(所有节点处)布置一张采用 XOR 规则的 IBLT。具体而言,当数据包 $X$ 到达时,将对应 IBLT 的 keySum ^= X.sig, count ++。由于这里参与异或的是 $X.sig$,因此需要同一个流的每个数据包 Sig 不同(不能采用五元组),否则同流的包之间会互相抵消。
与 ChameleMon 的问题相同,LossRadar 也将所有数据包在入口处染色处理、分多张表交替写入、等待延迟后拉取一整张表查询。这里等待的延迟不止包括单向时延,还需要额外给一个乱序的可容忍时间。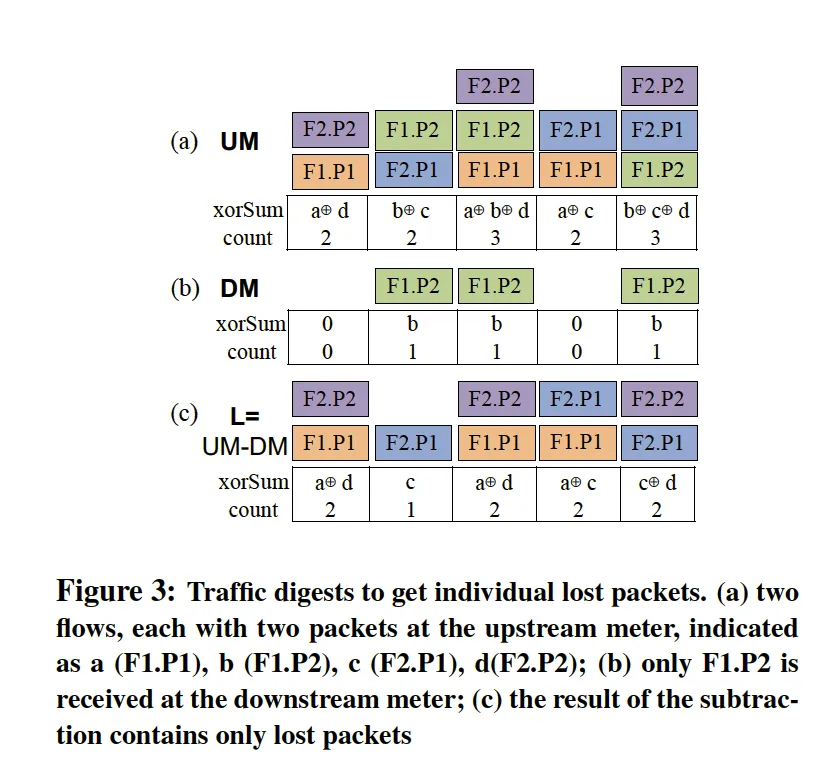
UnivMon
TODO
Facebook 基于他们的机房架构,设计了一套故障定位系统。他们没有直接侵入监控机房里的设备,而是从四层 TCP 的表现反推机房故障。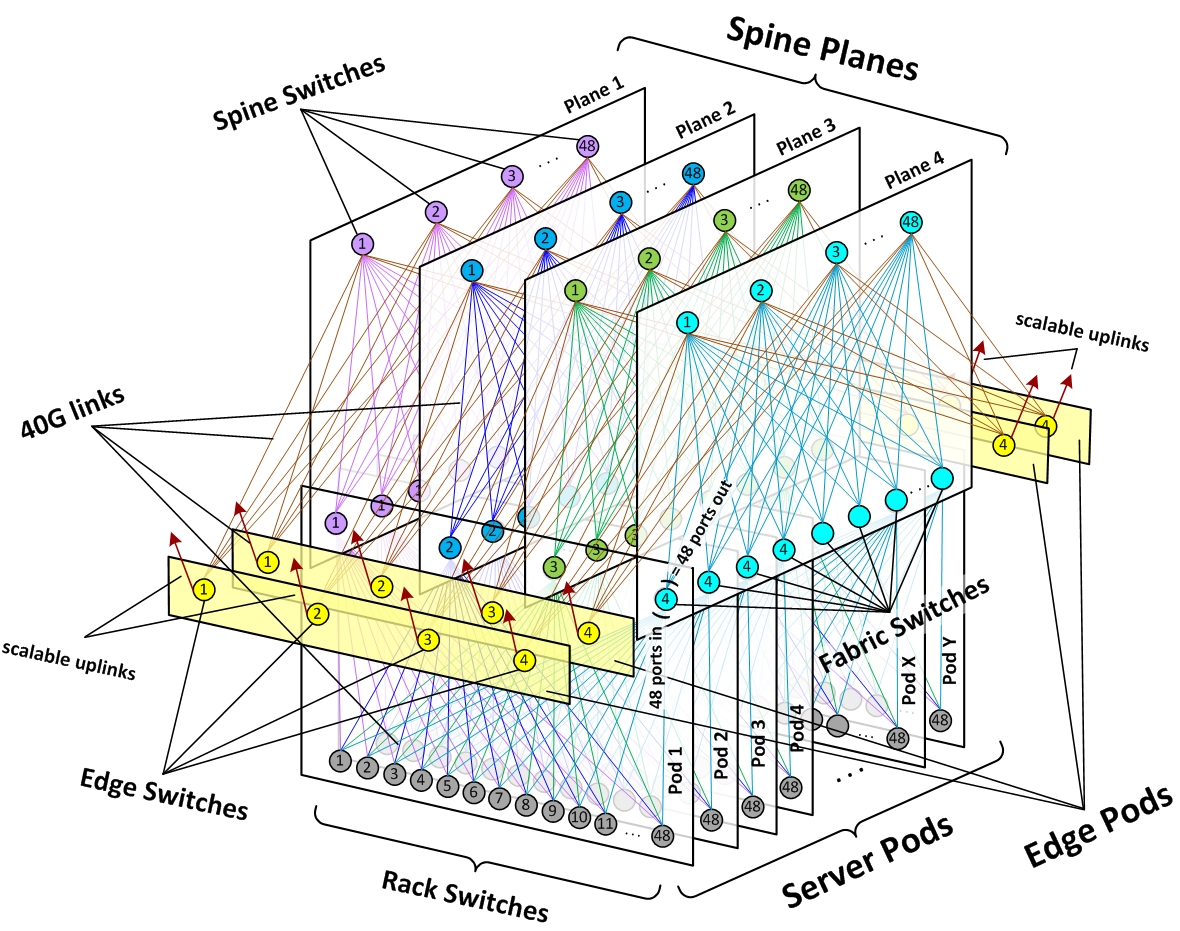
最下面灰色的是 ToR,每 48 个 ToR 构成一个 Pod。一个 Pod 内有 4 个 Agg Switch,每个 Agg 向下与每个 ToR 连接,向上与 Plane 内 Core Switch 连接。在同一个 Pod 内的两个 Agg 由于不属于同一个 Plane,因此不会连到同一个 Core。所以只要定位走了哪个 Core(和主机 ID),就能还原出整条链路。
基于此,Facebook 直接利用了三层协议 header 里的 IPv6 DSCP 字段标记 Core。事实上也可以使用其他字段,例如 TTL,但 Facebook 现网交换机暂时不支持。文章也提到了一种应对更通用的机房架构的方案:假设链路上有 $D$ 跳,每跳有 $C$ 种选择,我们从头到尾一层一层去遍历所有可能的交换机,如果某次遍历中了,那个交换机就把数据包里某个标志位置 $1$。相当于暴力把所有可能的机器全询问了一遍。这样在 $D\times C$ 个数据包以内,以 1 个 bit 为代价可以查询出链路。当然这里一定会需要一些方法标记当前查询的是哪个交换机,但论文里没算进空间开销,如果按 TCP 做也能直接用包编号代表查询编号,但需要交换机能根据查询编号 map 出查的是不是自己。
而后,使用这套系统检测带路径的 cwnd/ssthresh/srtt/retransmission/syscall-latency 数据,先根据路径进行分组聚合,得到每条路径对应的数据。然后再根据待分析的链路区间聚合,得到流经某个链路(如某个 Agg 到某个 Core)的所有流的数据的聚合。这些数据可以横向对比来分析某个具体的链路区间有没有出问题。Facebook 使用 T 检验来判断某个值是否是异常的(即判断「某个链路的对应值是异常的」这个假设的成立概率)。但这样会因为抖动产生假阳(本质是划分的粒度太细);Facebook 假设抖动的出现是均匀的,因此假阳的出现也是均匀的,所以 Controller 会聚合一段时间内的异常上报,再通过假设检验判断是否真的有异常。
ElasticSketch
ElasticSketch 想解决:在同一个网络测量域内,Elephant Flow 和 Mice Flow 很难同时精确测量的问题。ElasticSketch 设计了一个两级结构:前端的 Heavy Part 是一个 Hashtable,记录 Elephant Flow;后端的 Light Part 是一个 CMS,记录 Mice Flow。在 Hashtable 里,每个桶维护四个值:flowKey、vote+(映射到该桶中 ID 为 flowKey 的次数)、vote-(映射到该桶中 ID 不为 flowKey 的次数)、flag(该 flowKey 是否有一部分记录值在 CMS 中)。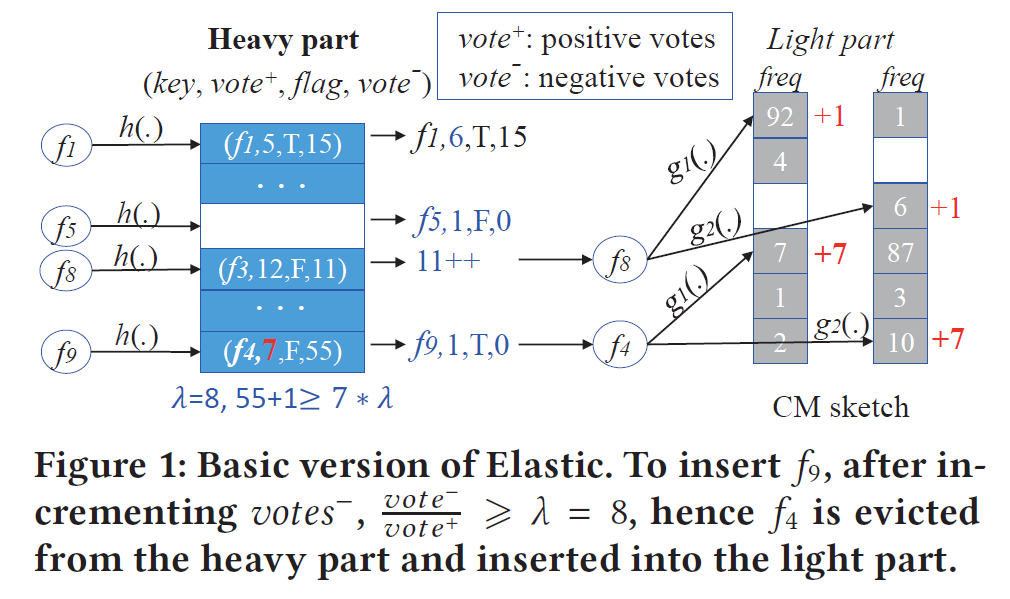
在插入数据包时,ElasticSketch 首先尝试将数据包插入 Hashtable 中。若无碰撞发生则直接更新即可;若有碰撞发生,则根据当前桶中元素的 vote-/vote+ 是否达到阈值来判断是否要驱逐桶中原本的元素。若不驱逐(认为桶中原有元素是重流),则将新插入的元素加入到 CMS 中;若驱逐(认为桶中原有元素不是重流),则将旧元素按 vote+ 记录的次数插入到 CMS 中,新元素占据 Hashtable 的这一项。在查询时,对于命中 Hashtable 的元素,还需要根据维护的 flag 位判断是否要进一步查询 CMS。
在此之外,ElasticSketch 还对以下几个方面进行了优化:
- 【压缩上报】由于上报时 CMS 占据了主要带宽,因此考虑压缩 CMS。具体方案为:将 CMS 横向划分为 $R$ 个一组,将所有每组对应位置上的元素取 Max;最终得到一个宽度为 $R$ 的压缩版 CMS。CMS 的合并与此前工作类似,直接按位取 Max 即可。
- 【瞬时高负载】考虑到网络中存在大量瞬时高负载场景,ElasticSketch 选择在高负载时只更新前端的 Hashtable。由于高负载本身代表了重流占据主导地位,因此对轻流记录的忽略是可接受的。
- 【自适应分布】ElasticSketch 支持前端 Hashtable 的动态空间调整。初始情况下,前端 Hashtable 只会被分配较小的空间;随着 Hashtable 的负载超过阈值,ElasticSketch 会以倍增的方式扩展 Hashtable(拷贝后删除不在新桶里的项即可)。在衡量负载时,ElasticSketch 设定了两个参数 $T_1,T_2$:当某个桶中所有流的负载都大于 $T_2$ 时,认为该桶已满;当超过 $T_1$ 个桶已满时,认为整个 Hashtable 需要扩容。
PINT
PINT 是基于 INT(In-band Network Telemetry)的。INT 的思路是:让 Switch 在数据包中插入数据,让接收端获得数据包传输过程中的测量信息。但这个做法在跳数较多时会严重浪费带宽。假设 INT 占用总带宽的比例从 $3%$ 上升到 $7%$,在原 Goodput 为 $70%$ 的情况下,INT 的变化将会使剩余容量下降到原来的 $1-\frac{1-0.7\times 1.07}{1-0.7\times 1.03}=0.47$ 倍。PINT 将 Switch 收集的数据分布在不同的数据包里,在接收端做聚合来还原完整数据,将额外开销限制在了一个固定值。
用户在一个 PINT 请求中,除了指定 value 和 aggregate function 以外,还可以指定 bit-budget 和 space-budget,分别代表每个包额外使用的最大空间,和客户端为处理每个流而 alloc 的最大空间。PINT 采用随机化的方式,将数据收集的任务概率性地指派给各 Switch,而后在接收端完成聚合。
在指派任务时,PINT 主要采用了三个方案:全局哈希、分布式编码、数据压缩。
- 全局哈希:PINT 让所有 Switch 和终端采用相同的哈希函数和伪随机数生成器。通过这种方法,无需一个中心化的服务器或分布式的协商就能完成任务指派和切分。Switch 直接对 $(packetID,hopNumber)$ 做哈希来判断自己是否需要操作该数据包。终端也能通过同样的哈希函数判断一个包被哪些 Switch 操作过。
- 分布式编码:PINT 采用概率性的编码实现分布式编码。例如让所有 Switch 都以蓄水池采样的方式将包中数据修改为自身数据,则对于一个跳数为 $k$ 的流,需要 $O(k\log k)$ 个包收集到所有 Switch 的数据。除此之外,也可以让每个 Switch 以概率 $p$ 将自身数据异或到包上,在终端实现解码。
- 数据压缩:我们可以对数据进行进一步压缩,例如除以 $D$ 存储(乘性误差)或对 $L$ 取 $\log$ 存储(加性误差)。这是一种变相的哈希,在传输某些稀疏值(例如 Switch ID)时可以使用。除此之外,在探测拥塞等不需要高精度统计的场景也可以酌情使用。

在聚合时,PINT 支持三种聚合方法:Per-Packet、Static Per-FLow、Dynamic Per-Flow。
- Per-Packet:让 Switch 直接运行聚合函数,在包传递的过程中完成聚合。适用于包粒度的检测,如拥塞探测。
- Static Per-Flow:让 Switch 用分布式编码保存数据,终端进行聚合。适用于流粒度的检测,如路径追踪。
- Dynamic Per-Flow:让 Switch 在运行聚合函数的同时,用分布式编码保存数据,终端进行解码和聚合。适用于同流不同包可能有差别的检测,如逐跳延迟查询。
DART
DART 认为可以通过测量 RTT 反映网络状况;作者认为:
- RTT 可以作为网络拥塞的标志
- RTT 监控对时延敏感的应用非常有帮助
- RTT 可以反映在线视频传输 QoE
- RTT 监控可以探测路由攻击
出于对 RTT 进行高精度连续实时监测的需要,DART 实现了一套基于 Tofino P4 的 RTT 实时检测系统。实现的基本思想仍然基于 TCP 的流控,通过观察上下行的 SeqNo 和 AckNo 对 timestamp 进行匹配,从而计算得到 RTT。由于测量设备位于 Host 和 User 的中间位置,因此需要双向的流监控才能得到完整的 RTT 信息。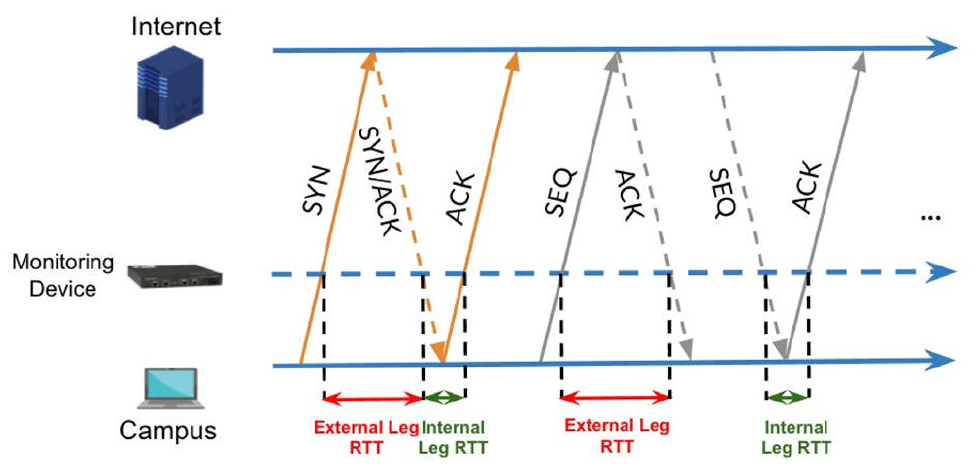
虽然 DART 在维护一个类似于 TCP 的滑动窗口,但其核心目标是进行 RTT 查询,而不是空洞的维护;因此,类似累计 ACK 的机制反而会影响 DART 计算出正确的 RTT。为了降低计算和存储压力,DART 设计了一个两步的流程:Range Tracker 维护每个活跃流(四元组)的有效序列号范围,将不可能计算出正确 RTT 的 ACK 和 SEQ 全部过滤掉;Packet Tracker 维护一个 SEQ 表,记录可能得到正确 RTT 的 SEQ-timestamp 对,直到一个对应的 ACK 到达用于计算出 RTT 并将对应的 SEQ 项从表中删去。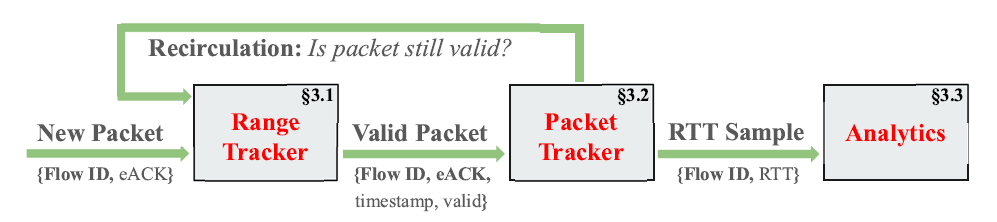
在设计了 RT-PT 的两步流程后,仍有可能会出现:被 RT 校验为合法的 SEQ,出于某些原因(连接中断、累积 ACK 等)在 PT 中被存储却一直无法得到对应的 ACK。DART 设计了 Lazy Eviction,即直到该 SEQ 占用的表项遇到 Hash Collision 之前,都一直保留该条 SEQ;这避免了引入 Timeout 机制或基于 TCP 流控的机制所带来的额外开销。当新的 SEQ-timestamp 对与 PT 表中某旧表项发声哈希碰撞时,为了防止旧表项被错误地过早驱逐,DART 会:首先将新表项插入 PT;其次驱逐旧表项;最后将旧表项视为一个新的 SEQ 对待,重新送回 RT 中进行检验并尝试插入 PT 表中。这在保证了正确性的同时,有效地排除了累计 ACK 机制带来的影响,降低了内存和计算开销。
这个循环驱逐的机制可能会导致两个有效的 SEQ 高频互相驱逐。DART 为此额外加入了一个循环探测,并为每个 SEQ 循环驱逐的次数设定上限。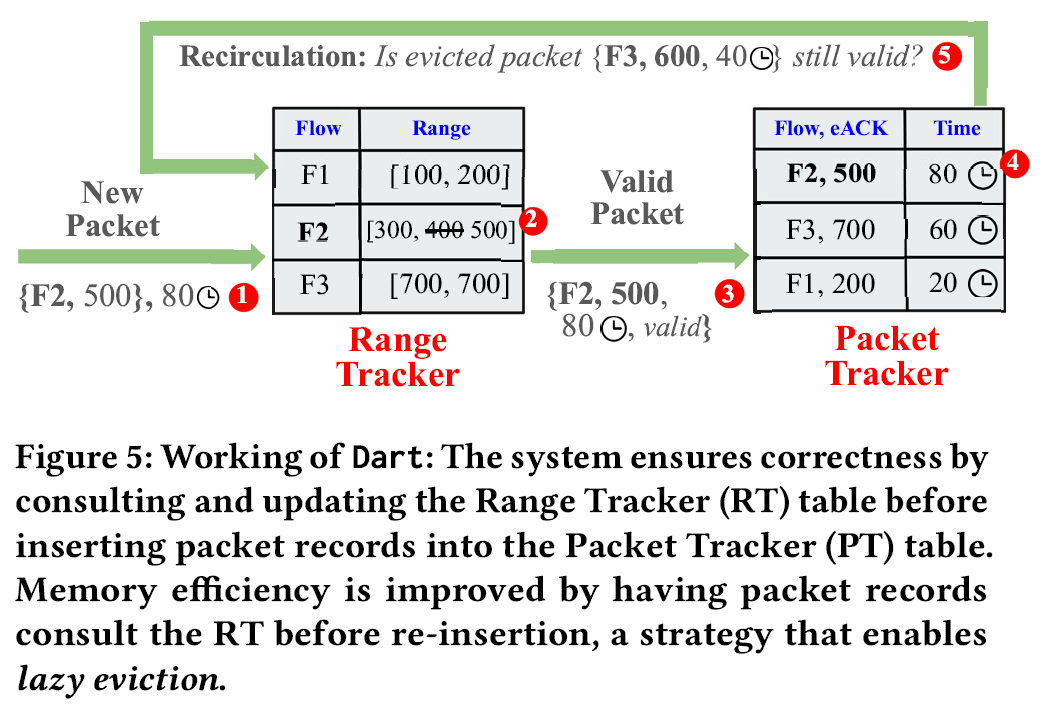
ChameleMon
ChameleMon 想解决的问题是:在有限的计算和存储资源下,既要支持 packet accumulation task(流量统计、大象流筛选等,主要使用各种 Sketch 来做),又要支持 packet loss tasks(丢包检测,主要使用 IBLT 和各种可编程交换机特性来做),还不想像 FlowRadar 那样维护所有流信息。为此,ChameleMon 将所有流分为三类:HH(Heavy-Hitter)、HL(Heavy-Loss)、LL(Light-Loss)。
ChameleMon 在 Ingress 处用一个 TowerSketch 做流分类(HH/HL/LL);在网络入口布置 HH/HL/LL 三个 FermatSketch,在网络出口布置 HL/LL 两个 FermatSketch。HH 的结果直接可用于 packet accumulation task;两组 HL/LL 之差可用于 packet loss tasks。控制面可以根据任务精度需要,实时地调整这几个 FermatSketch 占用的空间。由于 FermatSketch 支持直接横向加表以提高精度,所以不需要额外的维护操作。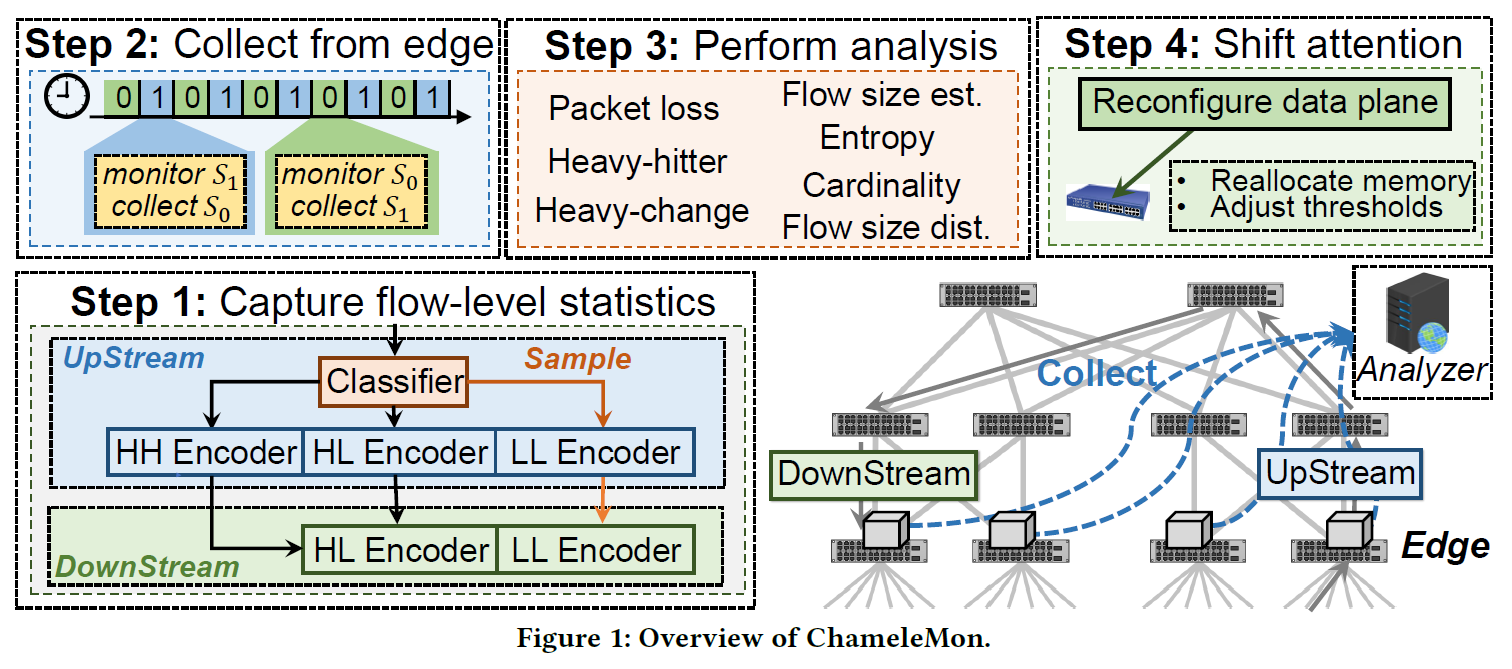
对于 packet loss tasks,需要注意出入口之间存在 inflight 的包。因此可以让入口给所有流入的包打一个 0/1 的标记(逻辑时钟),隔一段(相对于 rtt 较长的)时间翻转。同时,所有 Sketch 维护两份,对应逻辑时钟为 0/1 的数据。控制面在逻辑时钟翻转后等待一段时间(至少超过 stt)拉取 sketch 进行分析。