编译原理_期末复习
第三章 词法分析
- 词法分析的作用
- 词法单元的规约(正则表达式)
- 词法单元的识别(状态转换图/有穷自动机)
- 词法分析器生成工具及设计
词素/词法单元的区别:词素是输入的东西,词法单元是匹配出来的东西
模式:词法单元对应的词素可能具有的形式
正则表达式:Regular Expression;优先级:* > 连接符 > |
状态转换图、NFA、DFA:NFA拼接、RE转NFA、NFA转DFA、DFA最简化:见 FLA
第四章 语法分析
概念
- 句型/句子:句子不包含非终结符
- 语言:所有可接受的(推导出来的)句子的集合
消除二义性
- 此处不考;优先级上升算法处考
消除左递归
- 立即左递归的消除:$$A\to A\alpha_1|A\alpha_2|\cdots|A\alpha_n|\beta_1|\beta_2|\cdots|\beta_m$$改写为:$$A\to \beta_1A’|\beta_2A’|\cdots|\beta_mA’$$ $$A’\to \alpha_1A’|\alpha_2A’|\cdots|\alpha_nA’|\varepsilon$$
- 间接左递归的消除:对所有非终结符排序(例如:$S,A$);若排序在后面的终结符可以推出前面的终结符(例如:$A\to Sd$),则将前面的终结符替换掉(假设有 $S\to Ab|C$,则替换为$A\to Abd|Cd$);随后消除立即左递归即可。
提取左公因子
- 过于简单,不叙述
自顶向下语法分析
递归下降分析
- 搞不定就回溯
LL(1)文法:
- $\text{FIRST}(\alpha)$:从 $\alpha$ 开始推导得到的首个终结符号的集合
- 若 $X$ 为终结符,则 $\text{FIRST}(X)={X}$
- 若有 $X\to \alpha$,则 $\text{FIRST}(\alpha)\subset\text{FIRST}(X)$
- 若有 $X\to \alpha$,且 $\alpha\mathop{\Rightarrow}\limits^*\varepsilon$ ,则有 $\varepsilon\in\text{FIRST}(X)$
- 若有 $X\to \alpha\beta$,且 $\alpha\mathop{\Rightarrow}\limits^*\varepsilon$ ,则有 $\text{FIRST}(\beta)\subset\text{FIRST}(X)$
- $\text{FOLLOW}(A)$:在 $A$ 后面紧跟着的终结符的集合
- 注意要加上 $$$
- 按如下两个规则不断迭代,直到收敛为止:
- 直接推断:若存在 $A\to\alpha B\beta$,则 $\text{FIRST}(\beta)$ 中所有非 $\varepsilon$ 元素均在 $\text{FOLLOW}(B)$ 中
- 包含推断:若存在 $A\to \alpha B$,或 $A\to\alpha B\beta$ 且 $\beta\mathop{\Rightarrow}\limits^*\varepsilon$,则 $\text{FOLLOW}(A)\subset\text{FOLLOW}(B)$
- 根据 FIRST 和 FOLLOW 生成预测分析表
- 对于所有的产生式 $A\to \alpha$
- 对所有的 $a\in \text{FIRST}(\alpha)$,将 $A\to \alpha$ 加入 $M[A,a]$
- 若 $\varepsilon\in\text{FIRST}(\alpha)$,则对于所有的 $b\in\text{FOLLOW}(\alpha)$,将 $A\to\alpha$ 加入 $M[A,b]$
自底向上语法分析
移入-规约技术
- 移入-规约冲突
- 规约-规约冲突
LR(0)文法:
- LR(0) 项:$A\to XY\cdot Z$,表示已经扫描/规约到 $Y$ 之后,并期望接下来看到 $Z$
- 开始状态:$S’\to \cdot S$
- 增广文法、项集闭包CLOSURE、GOTO
- 增广文法:加入 $S’\to S$
- $\text{CLOSURE}(I)$:$I$ 的项集闭包
- 把 $I$ 本身的项集添加到 $\text{CLOSURE}(I)$ 中
- 若 $\text{CLOSURE}(I)$ 中存在 $A\to \alpha\cdot B\beta$,且有 $B\to\gamma$,则 $B\to\cdot\gamma \in \text{CLOSURE}(I)$
- $\text{GOTO}(I,X)$:对每一个文法符号 $X$(包含终结符和非终结符),计算 $\text{CLOSURE}(I)$ 中的每一个项集怎么变化:符合项集的把「点」右移一位,不符合项集的扔掉;最后再把得到的结果算一次闭包
- 本质上和 NFA 转 DFA 的过程相同
- LR(0) 自动机
- 按照 $\text{CLOSURE}$ 和 $\text{GOTO}$ 构造
- 分析表:ACTION 和 GOTO
SLR:
- 引入了 $\text{FOLLOW}$ 集
- 思想:把 $\alpha$ 归约成为 $A$,后面需是 $\text{FOLLOW}(A)$ 中的终结符号,否则只能移入
- 若 $[A\to\alpha\cdot a\beta]\in I_i$ 且 $\text{GOTO}(I_i,a)=I_j$,则 $\text{ACTION}(I_i,a)=\text{shift}$
- 若 $[A\to \alpha\cdot]\in I_i$ 且 $a\in\text{FOLLOW}(A)$,则 $\text{ACTION}(I_i,a)=\text{reduce}$
**LR(1)**:
- 向前多看一个字符,项集变为 $[A\to \alpha\cdot\beta,a]$
- 生成项集闭包时,由 $[A\to \alpha\cdot B\beta,a]$ 结合 $B\to\gamma$ 生成 $[B\to\cdot\gamma,b]$ 需要满足:
- $a\in \text{FOLLOW}(\gamma\beta)$
- $b\in\text{FIRST}(\beta a)$
- 生成 GOTO 时,对于 $[A\to\alpha\cdot,a]$ 生成 $\text{ACTION}(i,a)=$ “按照 $A\to\alpha$ 规约”
**LALR(1)**:
- 合并了 LR(1) 中核心相同的项(核心:项集的第一个分量)
第五章 语法制导的翻译
- SDD: Syntax Directed Definition
- SDT: Syntax Directed Translation
综合属性和继承属性
- 综合属性:只依赖自己和儿子
- 继承属性:依赖自己、儿子、父节点、兄弟节点
分析树
- 注释语法分析树:节点为 AST 中每个节点的所有属性的值,边旁边加属性箭头
- S 属性的SDD:只包含 S 属性的SDD,通常用 LR 实现
- L 属性的SDD:包含 L 属性的,通常用 LL 实现
- 将某个非终结符号 $A$ 的 L 属性计算放在其符号左侧:$X\to BC{A_L}A$
- 将 S 属性放在其产生式右侧:$X\to BC{A_L}A{X_S}$
- 栈实现:注意 $top-1$ 和 $top-2$,栈里还有符号
第六章 中间代码生成
表达式的有向无环图
- 注意数组
三地址代码
- $x=y\ op\ z$
- 四元式、三元式、间接三元式
静态单赋值(SSA: Static Single Assignment)
- 所有赋值都是针对名称不同的变量
- 使用 $\varphi$ 函数合并不同的定值
IFELSE / WHILE
- $\text{if}\ relop\ \text{goto}\ L$
- 短路
控制流语句的翻译
$$S\to\textbf{if}\ (\ B\ )\ S_1\ \textbf{else}\ S_2$$
- B 和 S 拥有综合属性 $code$,代表翻译出的代码
- B 拥有继承属性 $true$ 和 $false$,代表 B 为真/假时的跳转目标
- S 拥有继承属性 $next$,代表 S 执行完毕后的跳转目标
- $S_1.next,\ S_2.next\leftarrow S.next$
- $S.code=B.code\ |\ label(B.true)\ |\ S1.code\ |\ gen(‘\texttt{goto}’\ S.next)\ |\ label(B.false)\ |\ S2.code$
$$S\to\textbf{while}\ (\ B\ )\ S_1$$ - 相比于 $\textbf{if}$ 多了一个 $begin$
- $B.false \leftarrow S.next$
- $S1.next \leftarrow begin$
- $S.code=label(begin)\ |\ B.code\ |\ label(B.true)\ |\ S1.code\ |\ gen(‘\texttt{goto}’\ begin)\ |\ label(B.false)$
- 注意:$S.next$ 指向 $S$ 的后继,但不用 $S$ 本身操心怎么生成;即:其应该由 $S$ 的「调用者(父节点)」准备好
$$Bool\ Condition$$ - 注意短路
- 注意是求值还是跳转
- 回填方法:
- 原因:$\textbf{if}\ (\ B\ )\ S$,生成 $B$ 时不清楚失败时跳转到哪里($S$ 还未生成)
- 思想:维护一个 $truelist$ 和 $falselist$,存放所有需要跳转的目标(以求值为例):

第七章 运行时环境
- 堆栈管理
- 垃圾回收
活动记录(栈管理)
- 包含:实参、返回值、控制链、访问链、保存的机器状态、局部数据、临时变量
- 函数调用:传递参数/传递返回值(数据方面)、正确跳转/正确跳回(控制方面)
- 注意静态数据和全局变量,在静态数据区里
垃圾回收(堆管理)
- 引用计数
- 基于区域的分配
- 标记-清扫式垃圾回收(根集:全局、静态、栈上)
- 拷贝-回收式垃圾回收
第八章 目标代码生成
- 基本块和流图
- 基本块优化方法
- 寄存器指派与分配方法
基本块
- 基本块的划分
- 基本块的优化
DAG的表示
- 注意数组
- 基于 DAG 的优化:死代码消除、局部公共子表达式等
- 数组引用:数组中被赋值就杀死了数组中所有的值
- 指针:指针被赋值就杀死了所有被指针指向的值
描述符
- 寄存器描述符:描述一个寄存器存储了哪些变量
- 地址描述符:描述某一个变量存在的位置(包括寄存器和内存位置)
- 赋值:寄存器描述符的改变;可能在赋值后,$x$ 不在 $x$ 自己的地址描述符中
- 注意需要同步修改地址描述符
第九章 机器无关优化
优化的来源
- 全局公共子表达式
- 复制传播
- 死代码消除
- 代码移动
- 归纳变量和强度削减
数据流分析
- 到达定值分析
- 正向分析,分析对象为定值语句
- 初始化:$\text{OUT}[Entry]=\emptyset$
- $gen_B$:基本块 $B$ 中被定义且向下可见的定值
- $kill_B$:基本块 $B$ 中被杀死的定值
- $\text{IN}B=\cup{B’\to B}\ \text{OUT}_B$
- $\text{OUT}_B=gen_B\cup(\text{IN}_B-kill_B)$
- 活跃变量分析
- 逆向分析,分析对象为变量
- 初始化:$IN[Exit]=\emptyset$
- $def_B$:基本块 $B$ 中定值先于使用的变量
- $use_B$:基本块 $B$ 中使用先于定值的变量
- $\text{IN}_B=use_B\cup(\text{OUT}_B-def_B)$
- $\text{OUT}B=\cup{B\to B’}\ \text{IN}_{B’}$
- 可用表达式分析
- 正向分析,分析对象为表达式
- 初始化:$\text{OUT}[Entry]=\emptyset$,其他基本块有 $\text{OUT}_B=U$
- $e_gen_B$:基本块 $B$ 中被定义且向下可见的表达式
- $e_kill_B$:基本块 $B$ 中被杀死的表达式
- $\text{IN}B=\cap{B’\to B}\ \text{OUT}_{B’}$
- $\text{OUT}_B=e_gen_B\cup(\text{IN}_B-e_kill_B)$
- 自然循环与支配树
- 支配:$i$ 支配 $j$ 意为从出发点开始所有到达 $j$ 的路径都经过 $i$
- 容易证明支配关系图是一棵树
- 直接支配:最后一个支配该节点的节点
- 使用数据流分析:
- 正向分析,分析对象为基本块
- 初始化:$\text{OUT}[Entry]={Entry}$,其他基本块有 $\text{OUT}_B=\emptyset$
- $\text{IN}B=\cap{B’\to B}\ \text{OUT}_{B’}$
- $\text{OUT}_B=\text{IN}_B\cup{B}$
- 回边:$a\to b$,若 $b$ 支配了 $a$,则其称为回边
- 若所有后退边都是回边,则流图是可规约的
- 深度:所有无环路径上,回边的最大数量
- 自然循环:对于回边 $a\to b$,其自然循环为:不经过 $b$ 就能到达 $a$ 的点的集合(包括 $b$)
- 支配:$i$ 支配 $j$ 意为从出发点开始所有到达 $j$ 的路径都经过 $i$
循环的优化
- 归纳变量与强度削减
补充部分
JIT
- 即时编译(Just-In-Time)
- 思想:在运行过程中实时统计 Hot Code,将这部分代码编译为机器码以加速执行
优先级上升算法
- 用于消除二义性
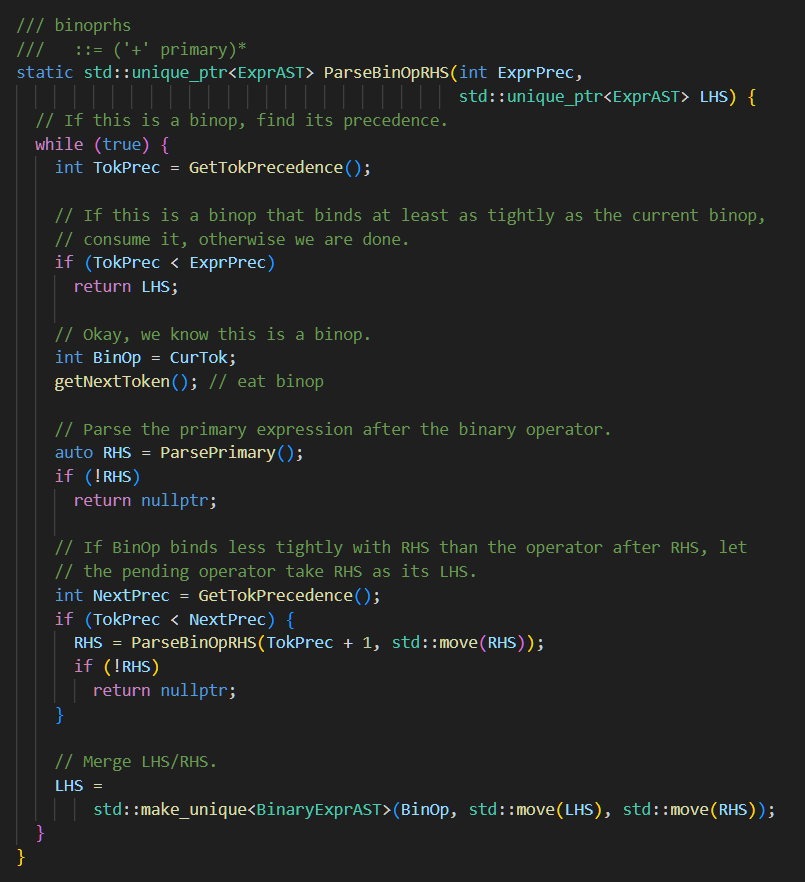
- LHS 维护当前已经 parse 的 AST
- 整个函数负责 parse 一个已知为 RHS 的串
- 举例:$a+b+(c+d)\times e+f$,假设 $+$ 优先级为 $20$,$\times$ 优先级为 $40$
- 第一次拿到 LHS 为 $a$、RHS 为 $b$、BinOp 为 $+$;$TokPrec=20,ExprPrec=0,NextPrec=20$
- 第一次结束后 Merge 了 LHS 和 RHS,于是 LHS 变为 $a+b$
- 第二次拿到 RHS 为 $(c+d)$(ParsePrimary 拿到一个完整的单元算式)、BinOp 为 $+$;$TokPrec=20,ExprPrec=0,NextPrec=40$
- 于是第二次满足 $TokPrec<NextPrec$,单独对 RHS 递归 ParseBinOpRHS
- 为了让 $(c+d)$ 在看到 $\times$ 时继续右结合,在看到 $+$ 时立刻返回,规定在 $TokPrec<ExprPrec$ 时立刻返回;这也是递归时让 $ExprPrec=TokPrec+1$ 的用意
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 IAD's Blog!