编译原理_实验报告
Lab 1
编译方法
在 Code 文件夹下输入命令 make 即可自动编译生成 parser 文件。
功能简介
文件结构如下所示:
1 | Code |
其中 lexical.h 存放与词法分析相关的 flex 代码;syntax.y 存放与语法分析相关的 bison 代码和 main 函数;syntaxtree.h 和 syntaxtree.c 用于存放与语法树相关的结构体定义和函数。
词法分析
对于ID、INT和FLOAT,我使用了这样的正则表达式:
1 | INT 0|([1-9][0-9]*) |
在分析时需要注意优先级,例如先匹配 /*、最后匹配ID等。
在匹配到 /* 时,我将不断向后读取内容直到遇到第一个 */,并将中间的内容全部丢弃。
语法分析
在语法分析中,我将所有节点的类型自定义为语法树的节点指针。在推导成功后,我构造一个语法树的节点,并将当前词素的值赋为指向构造出的节点的指针,即 $$ = Constructor(...)。
在错误处理中,我在不产生移入规约冲突的前提下加入了尽可能多的错误处理。当产生冲突时尽量选择抽象层较高的词素进行错误处理。同时,我设计了一些包含多个错误的测试样例,在错误恢复不能正常工作时,我尝试将所有错误改正后,根据正确情况下的语法树查找应当在何处进行错误恢复,并返回到 syntax.y 中对应位置进行改正。
有时,加入的错误处理语句本身与推导式产生了冲突(例如 CompSt : LC DefList StmtList RC 和 CompSt : LC error RC)。此时可以单独执行 bison 并加上 -Wcounterexamples 得到一个会产生冲突的例子,方便进一步分析和设计错误处理。
为了防止对同一个错误同时报错(例如:struct :; 会同时引发A和B两种报错),我定义了 haserror[] 数组,对于同一行只报一次错。
语法树
我的语法树如下设计:
- 存在且仅存在一个根节点
- 每个节点在保存子节点时仅保存第一个
- 每个节点以链表形式保存其兄弟节点(以上两条见代码中注释图例)
- 每个节点保存:词素名称、词素内容(若为ID, FLOAT, INT, TYPE)、是否为终结符、行号
如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22typedef struct Node {
char *lex_name;
char *content;
int type;
int line;
struct Node* fa;
struct Node* next;
struct Node* son;
union {
unsigned int int_value;
float float_value;
};
/*
[<fa>]
|
[son]----------------------------[son->next]---...
| |
[son->son]-[son->son->next]-... [son->next->son]-[son->next->son->next]-...
*/
} Node;
其提供如下四个成员函数:
1 | Node* Constructor(char *lex_name, char *content, int type, int line); |
在为节点添加儿子时,考虑到语法树构建的特点,程序会 assert 当前父节点没有儿子、当前所有儿子节点没有兄弟。Node *root 定义在 syntaxtree.c 中,并在 syntax.y 中通过 extern 导入符号。其余实现较为常规,见代码。
Lab 2
编译方法
在 Code 文件夹下输入命令 make 即可自动编译生成 parser 文件。
功能简介
文件结构如下所示:
1 | Code |
Lab 1:lexical.h 存放与词法分析相关的 flex 代码;syntax.y 存放与语法分析相关的 bison 代码;syntaxtree.h 和 syntaxtree.c 用于存放与语法树相关的结构体定义和函数。
Lab 2:main.c 存放主函数;symboltable.c 和 symboltable.h 存放与类型相关的结构体、函数和已定义的 Symbol/Structure/Function 表;semantic.c 和 semantic.h 存放进行语义分析的函数。
类型表示
我使用手册中推荐的方式存储类型,定义了如下的结构体:
1 | struct Type { |
成员及作用见注释。
这里想强调:类型是纯粹的类型,不含有任何与变量本身相关的信息(名称、是否为左值等)。与变量相关的信息需要额外存储(例如:结构体中域名存储在 FieldList 中)。
结构体在存储时使用链表存储,链表项为 FieldList,其中存储了该项的名称和类型;函数在存储时,存储名称、返回类型、参数数量和参数列表;参数列表的每一项 FunctionArg 存储该项的形参类型。
为了避免重复的代码,我为涉及到以上结构体和数组的操作尽最大可能进行封装,在 semantic.c 中尽量只使用以下的函数进行操作:
1 | // CONSTRUCT |
这样做的好处还在于可以进行单元测试。我单独为 symboltable.c 中的函数设计了测试,但由于后续接口发生变动,测试代码没有反馈在最终版本的提交中。
AST遍历
对于每一个非终结符,我编写了一个对应的函数进行解析。为了方便起见,我加入了 Node* getSon(Node* node, char* name) 函数用于获取一个终结符的特定名称的儿子。
使用 getSon 进行AST的遍历是十分有必要的,因为遍历时不能提前确定某个儿子是否存在。例如:$CompSt\to LC\ DefList\ StmtList\ RC$,虽然 $CompSt$ 和 $DefList$ 都没有直接推导出 $\varepsilon$
的能力,但是 $DefList$ 可能会经过多步推导规约为 $\varepsilon$,从而不存在于AST中。于是,可能会出现 $CompSt$ 的子节点只有 $LC\ StmtList\ RC$ 的情况。所以为了能够精确判别和定位某个子节点,应该使用 getSon 而不是直接以 node->son->next->next 的指针形式访问子节点。
为了简化程序(不显式地引入综合属性和继承属性),我利用递归的传参完成了属性的传递。对于inh属性向下传递,我将其放置在下层函数的参数中;对于inh属性的向上传递,我将其放置在下层函数的返回值中。使用这样的方法,我让程序更加简洁易懂。例如:Type* Specifier(Node* node) 返回解析好的 Specifier 的类型指针;void Stmt(Node* node, Function* func) 在正常的结点指针之外额外接受一个当前所在的函数,用于在遇到 RETURN 时判定返回值是否合法。
此外的内容按照手册和文法进行判别即可。
Lab 3
编译方法
在 Code 文件夹下输入命令 make 即可自动编译生成 parser 文件。
功能简介
文件结构如下所示:
1 | Code |
Lab 1:lexical.h 存放与词法分析相关的 flex 代码;syntax.y 存放与语法分析相关的 bison 代码;syntaxtree.h 和 syntaxtree.c 用于存放与语法树相关的结构体定义和函数。
Lab 2:symboltable.c 和 symboltable.h 存放与类型相关的结构体、函数和已定义的 Symbol/Structure/Function 表;semantic.c 和 semantic.h 存放进行语义分析的函数。
Lab 3:main.c 存放主函数;intercode.h 和 intercode.c 存放与中间代码的构造与操作相关的定义和函数;translate.h 和 translate.c 存放与翻译的函数。
IR表示
我使用双向链表存储IR,如下所示:
1 | struct InterCodes { |
成员及作用见注释。
除此之外,我提供了对于IR的封装函数。任何与IR相关的修改或构造操作都必须使用封装的函数完成:
1 | // new |
其中 ParamPass 用于查询一个非基础的变量是否是通过传参被传递的。如果是,则说明该变量需要以引用形式进行访存。append_InterCode 和 append_InterCodes 分别会将存储单条IR/IR链表的 cur 拼接到 target 后方。
翻译
使用文档中给出的SDT即可。这里对于未提及的结构体和数组的翻译做出说明:
我在 semantic.h/.c 中添加了 int getTypeSize(Type* ty); 函数,用于返回一个特定的类型的总字节数;同时修改了 symboltable.h 中对于 Type 的定义:对于结构体类型新增 int stru_size; 用于存储结构体总字节数,同时在 FieldList 中新增 offset 项存储每一个项相对于结构体本身的偏移量、对于数组类型新增 int elem_size; 用于存储数组中元素的字节数。以上新增的信息全部在语义分析的过程中完成处理,在翻译过程中直接使用即可。
在处理赋值语句时,需要对左值的类型进行推导,具体会有以下情况:
- 左值是一个 EXP DOT ID,此时是结构体
- 左值是一个 EXP LB EXP RB,此时是数组
- 左值是一个 ID,此时可以直接赋值
我实现了Offset_Query translate_Exp_Offset(Node* node, char* place)函数,它会递归地将当前项相对于其父项的偏移累加到 place 中,并返回累加所需要的 IR 和当前分析到的 Type。递归地终止条件是遇到了第三种情况(左值是一个ID),此时递归终止,并层层向上返回。返回的途中会完成 IR 的生成和拼接。
需要注意的是,C–允许数组之间的直接赋值。因此在赋值时,需要额外留意左值是否是一个未展开的数组。这可以通过此前实现的 translate_Exp_Offset 的返回值中对类型的描述完成判断:若整体类型为 BASIC 则直接赋值;反之生成将整个数组全部赋值的代码(不断在指针间赋值,赋值一次后两个指针同时+4)。
此外的内容按照手册和文法进行判别即可。
测试数据补强
这里贴出一个在对于选做一的强测试数据(错误程序可通过OJ,但不能通过该测试数据):
1 | struct STRUCT_T { |
期望的输出是 114514。该测试数据的测试范围包括:
- 包含数组的结构体、结构体互相嵌套
- 结构体的局部定义和传参
- 结构体中数组整体赋值、赋值语句的返回值
- 数组在定义时直接赋值
Lab 4
编译方法
在 Code 文件夹下输入命令 make 即可自动编译生成 parser 文件。
功能简介
文件结构如下所示:
1 | Code |
Lab 1:lexical.h 存放与词法分析相关的 flex 代码;syntax.y 存放与语法分析相关的 bison 代码;syntaxtree.h 和 syntaxtree.c 用于存放与语法树相关的结构体定义和函数。
Lab 2:symboltable.c 和 symboltable.h 存放与类型相关的结构体、函数和已定义的 Symbol/Structure/Function 表;semantic.c 和 semantic.h 存放进行语义分析的函数。
Lab 3:main.c 存放主函数;intercode.h 和 intercode.c 存放与中间代码的构造与操作相关的定义和函数;translate.h 和 translate.c 存放与翻译的函数。
Lab 4:mipscode.h 和 mipscode.c 用于存放把 IR 翻译为 MIPS 汇编的函数。
MIPS语句容器
由于本系列实验后续不再基于 MIPS 汇编进一步操作,因此本实验中直接将 MIPS 汇编以字符串形式存储;与 IR 类似,依然使用链表形式进行存储:
1 | struct MipsCodes { |
我为 MIPS 汇编设计了如下的封装函数和宏定义:
1 | MipsCode* get_MipsCode(char* fmt, ...); |
因此在添加语句时,只需要保证已经定义过 MipsCodes* mc 即可直接使用类似 AM(" sw $t0, %d($sp)", x_offset); 的类 stdio 格式便捷地进行翻译。
寄存器分配与管理采用朴素分配法,即所有变量均存储在内存中,因此不做阐述
栈管理
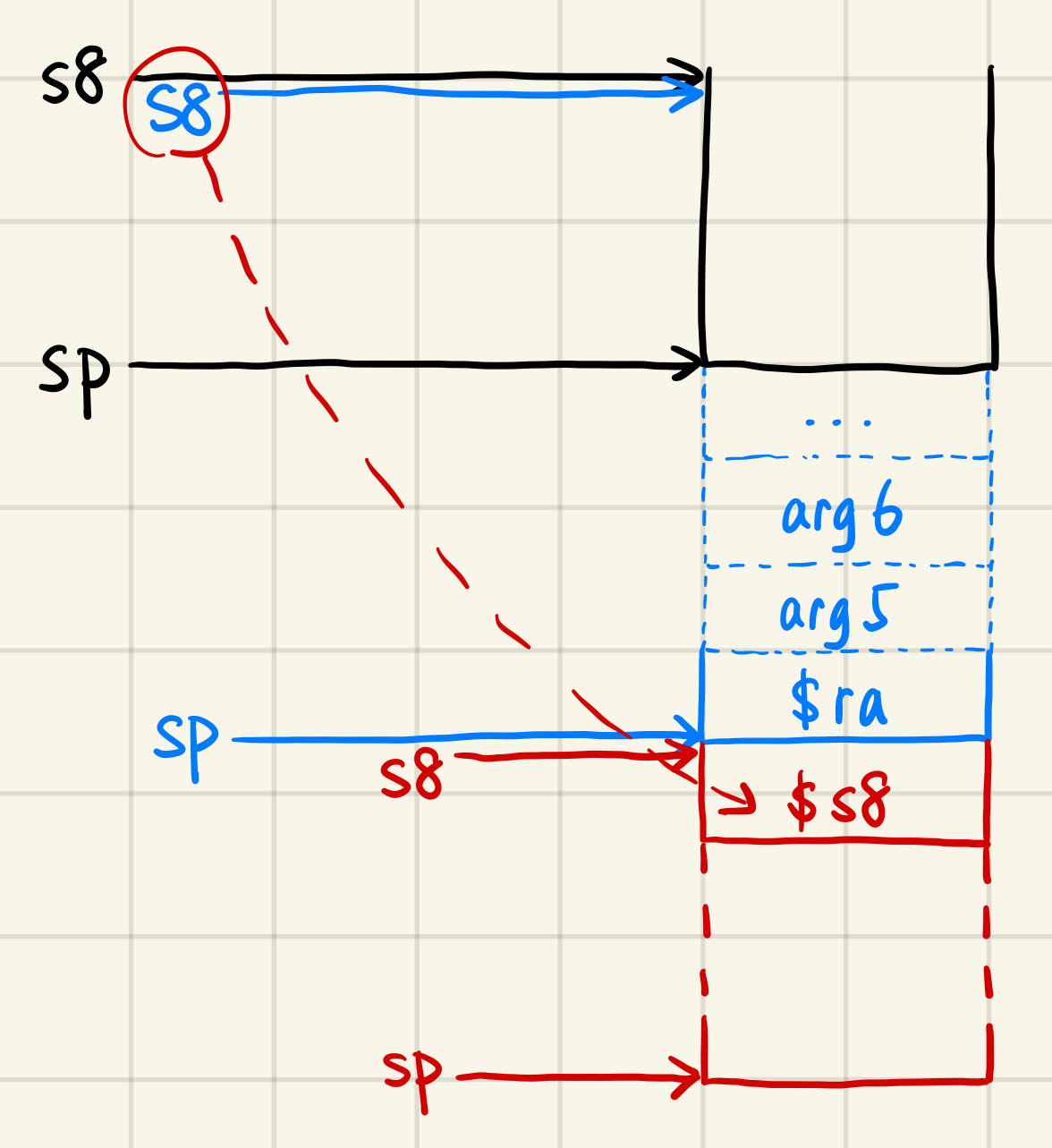
我的栈管理方式可以用下图表示:(图见下页)
- 黑色:原始状态
- 蓝色:调用者 CALL 之后的状态
- 红色:被调用者初始化后的状态
遵循以下原则:
- 所有临时变量的偏移量以
$sp为基准 - 所有栈传递参数的偏移量以
$s8为基准 - 函数调用和返回时,需要保存和恢复
$sp、$s8的值
因此过程处理如下:
- 函数开始时,统计本函数内部所需的临时空间大小,将
sp下移对应距离 - 函数调用时:(如有栈传参)**先固定
sp**,在sp下方保存参数,然后将sp下移对应距离;然后将sp下移 4 字节,保存s8;然后将s8移至原sp处 - 函数返回时:先保存返回值;然后将
sp移至s8处;然后从-4($sp)处取出原s8并恢复
需要注意的是:
- 必须在函数开始时分配好所有本函数的临时变量空间,**不可以用一个开一个,即:不可以遇到新变量时临时
addi $sp, $sp, -4**。原因在于:编译时无法预测分支是否会执行,因此无法确定分支后的sp相对于分支前的变量的实际偏移量。 - 整个过程,除函数调用外,不得对
sp产生任何更改,否则会导致偏移错误。函数调用也需要在返回后立即将sp修正为原值。
令人头大的手册大坑
手册中自带的哈希函数,会将 _t19 和 _t25 映射到同一个值。经测试,这是算法本身导致的碰撞,无法通过增大映射空间的方式解决。
Lab 5
编译方法
在 Code 文件夹下输入命令 make 即可自动编译生成 parser 文件。
功能简介
采用了下发的框架,进行了修改的部分如下所示:
1 | └── src |
按照框架完成所有 TODO 内容即可。
后向求解器
- 将前向求解器逆向实现即可
- 框架代码写的有点坑:
transferBlock函数固定以in_fact、out_fact顺序传参,内部根据求解器方向决定传递方向,而不是固定将参数前者传递至参数后者
常量传播
- 常量传播为正向迭代
- 计算过程中 NAC 优先级最高,需要最先考虑
updateValue仅在赋值为 UNDEF 时使用到,其余情况均使用meetValue
复制传播
- 复制传播为正向迭代
- 使用
def-use对更新时,同时更新双方的映射规则
活跃变量分析
- 活跃变量分析为逆向迭代
- 根据迭代方程,应当先 kill 后 gen
- 当出现未被 def 的代码时,判定为死代码
可用表达式分析
- 可用表达式分析为正向迭代
- 向下传播时应该将可用表达式取交集传递
- 需要将所有非 ENTRY 的块的 OUT 初始化为全集