CS149_Lab1
Prog1
我使用 WSL 进行评测,开放给 WSL 使用的有 8 个 i7-13700H,每个CPU有 4 个核心。
宏观性能度量
将图像简单切割进行分配,得到度量如下:
| nThreads | v1-Speedup | v2-Speedup |
|---|---|---|
| 1 | 0.99x | 0.99x |
| 2 | 2.01x | 1.70x |
| 3 | 1.65x | 2.19x |
| 4 | 2.48x | 2.56x |
| 5 | 2.50x | 2.89x |
| 6 | 3.30x | 3.31x |
| 7 | 3.45x | 3.81x |
| 8 | 4.08x | 4.11x |
| 9 | 4.34x | 4.52x |
| 10 | 5.02x | 4.74x |
图片如下所示。在 nThreads=3 时明显会产生负载不均衡,负责处理中间图像的线程任务过重。

因此考虑将图像按每 $10$ 行拆分轮流交给每个线程负责。度量出的数据如下:
| nThreads | v1-Speedup | v2-Speedup |
|---|---|---|
| 1 | 1.01x | 1.00x |
| 2 | 1.99x | 1.99x |
| 3 | 3.05x | 3.00x |
| 4 | 3.96x | 3.86x |
| 5 | 4.89x | 4.59x |
| 6 | 5.87x | 5.45x |
| 7 | 6.73x | 5.87x |
| 8 | 7.13x | 6.75x |
| 9 | 5.66x | 5.49x |
| 10 | 5.69x | 6.26x |
观察到在 nThread <= 4 时基本符合了线性加速,此时四个线程全部在同一个CPU上运行,额外开销极低。在 nThread > 8 时产生了严重的 overhead,性能下降。
在经过了一些常数调整后,达到了 nThread=8 时 v1-Speedup: 7.51x, v2-Speedup: 6.93x。
Prog2
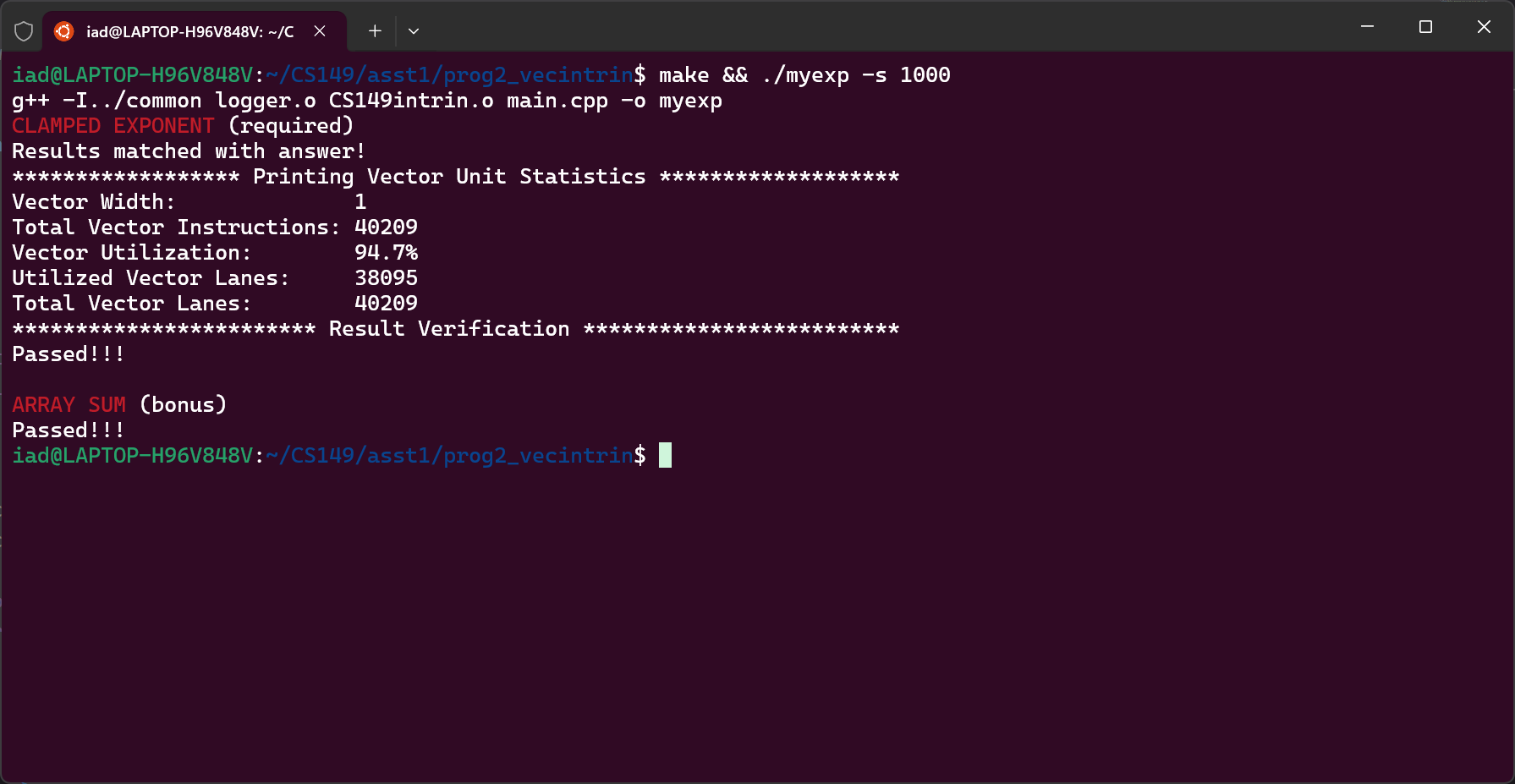
按照头文件定义的指令操作即可。在处理 VECTOR_WIDTH 越界时将操作窗口左移,导致某些数重复计算,但在数据量增大时比例趋近于0;对于 Bonus:将每个窗口不断应用 hadd 和 interleave,最后取结果的首位为答案即可。
1 | float arraySumVector(float* values, int N) { |
Prog3
直接编译运行可以获得 3.57x 的加速比。考虑到我的单CPU只有 4 核心,且SIMD指令只能针对单CPU进行并行优化,因此这个加速比例是合理的;在使用SPMD后,可获得 7.18x 的加速比:使用了两个 CPU,因此接近 8x 的加速比是合理的。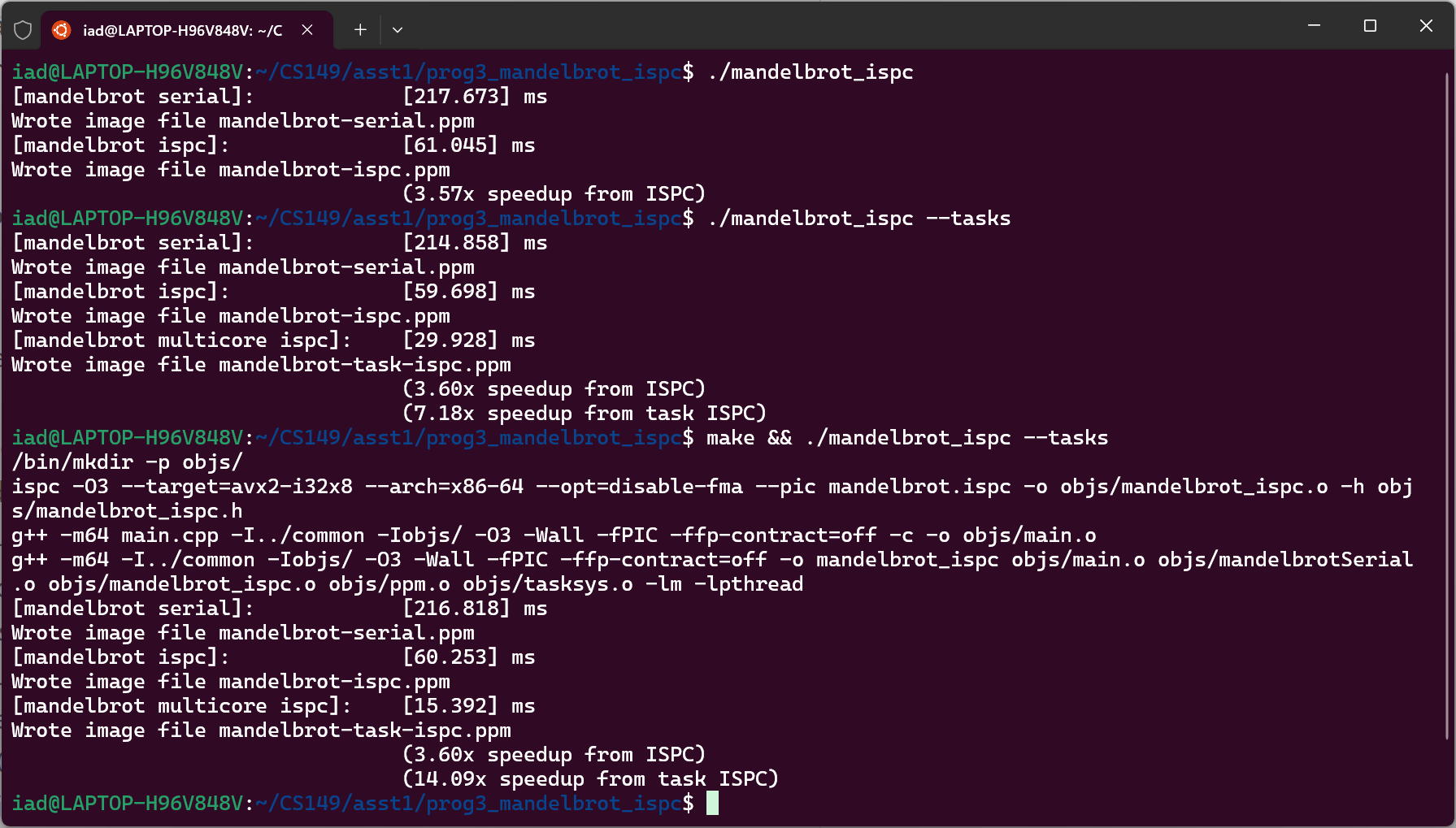
调整 N_TASK,最大可以获得 24.51x 的加速比,但是加速比在 N_TASK 达到 32 后不再增加。这是因为达到了总 CPU 的总核心数。
当我们生成10000个TASK时,与生成10000个THREAD相比,效率上会高得多:task是SIMD提供的抽象,编译器会将其以合适的分组进行重排。在重排之后,程序与 Prog2 中手写的SIMD指令无异,因此也不涉及上下文保护、栈空间切换、线程调度等操作。
Prog4
将 values[] 设为以下的不同值,得到加速比为:
| values | ISPC-Speedup | task-ISPC-Speedup |
|---|---|---|
| rand() | 3.73x | 27.30x |
| 1.f | 1.81x | 2.02x |
| 2.99999f | 4.55x | 41.07x |
思路:对于迭代次数较多的任务,额外overhead占比较低,因此加速比最大。
延续这样的思路,我们可以得到一个最慢的加速比。考虑每 8 个数字中有一个 2.99999f,所有的SIMD指令运行时间都会退化到最慢。这样可以得到 0.80x 的加速比(减速比)。
Bonus:使用 AVX2 实现开根迭代算法。第一遍写完之后一直在报 Segmentation Fault,插桩调了半天越调越神秘;gdb 调试发现崩在了 45 __m256 x = _mm256_load_ps(values + i);。联想到 jyyOS 中 M2 实验里的提示:
观察到原始数组没有满足对齐要求,于是使用 c++11 提供的 aligned_alloc 替代框架代码中的 new,问题解决;最终获得了 3.60x 的加速。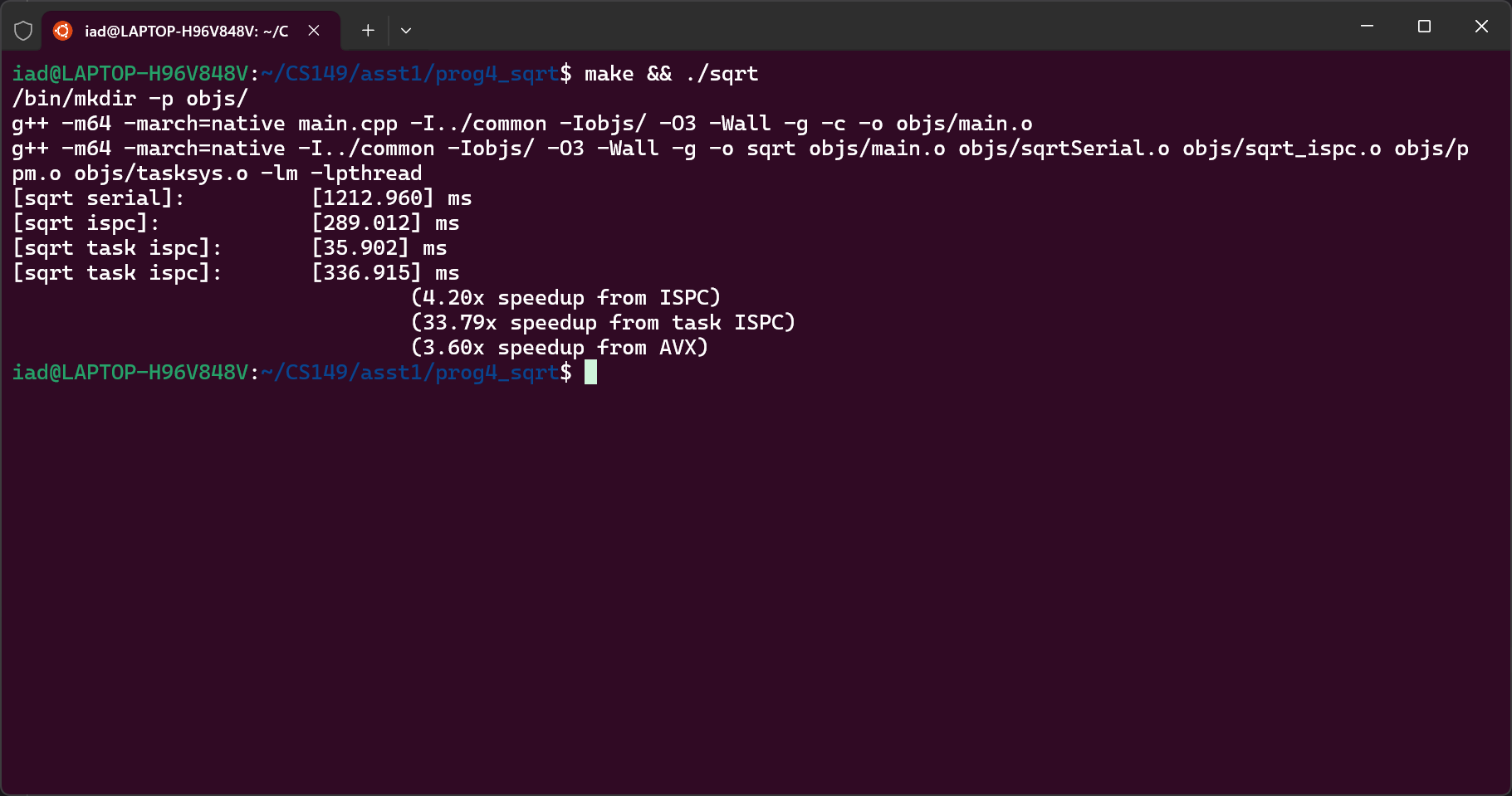
1 | void Print(__m256 v) { |
Prog5
更改 TASK 数量,得到:
| nTasks | task-Speedup |
|---|---|
| 1 | 0.70x |
| 2 | 1.25x |
| 4 | 1.18x |
| 8 | 2.07x |
| 16 | 1.37x |
| 32 | 1.80x |
在 TASK 数量超过 CPU 数量后,加速比显著下降。尝试将 N 放大,把数据量扩大到 1.25G(再大会被本机 kill 或者段错误),仍然符合上述规律,并没有在本机上观察到内存带宽造成的性能瓶颈。
Prog6
非常类似于 jyyOS 2024 的 M3[gpt.c],加之本题无法获得模型文件故而不做。